



Modelling in practice is a new series at DHI that explores how modelling helps us interpret complex water environments and turn scientific insights into practical decisions.
In this Q&A, we talk with Henrik Andersson, Technical Lead – Python Ecosystem at DHI. He shares his perspective on how Python is used around models in his work, not as a modelling method in itself, but as a practical way to connect models, data and assumptions when workflows become more complex.
Q: Python is often associated with data analysis. In your experience, how does it fit into modelling work?
Python is often referred to as a glue language, and that description fits well in MIKE modelling workflows. It connects the pieces that wouldn’t otherwise talk to each other; it enables automation of the repetitive parts, running scenarios, processing outputs, feeding results into reports, and it allows experts to colour outside the lines of what the MIKE tools support out of the box. MIKE is built around a great UI, and that’s genuinely where most users live. But Python is what makes the whole workflow stick together when you need to go beyond that.
Q: How has your experience with operational forecasting shaped the way you use and design Python tools for modelling workflows?
I have experience with running marine forecasts twice a day, predicting storm surges, current, waves, algal blooms, bacteria in bathing waters, etc. In an operational system, automation isn’t optional; the simulation has to run whether you’re there or not. For many years, that automation was built in VBscript and C#, not Python. It worked, but it was painful because I had to build everything from very basic components.
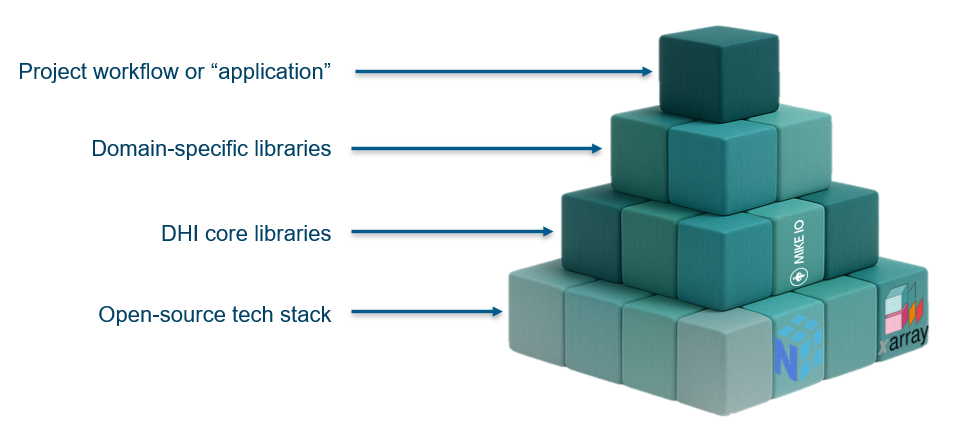
I applied my experience from forecasting and from several research projects when we designed MIKE IO . I knew exactly what I needed as a modeller from a Python library when orchestrating complex workflows, because I had felt the friction of doing it without one. The real difference with the Python ecosystem is that it has reliable libraries for working with scientific data, reading data in every possible format.
Q: From your perspective, when does it make sense to introduce Python into a modelling workflow?
If you are doing the same manual step more than a few times, opening a file, reformatting it, running the model, copying a number into a table, that’s a candidate for automation, and Python is not the only option, but currently one of the best choices for automation. It is also relevant for reproducibility: when the result needs to be handed to someone else, reviewed or revisited six months later. A manual workflow that lives in someone’s memory doesn’t survive that. Personally, my threshold for automation is very low; if I have to do it more than once, I’ll script it. But I respect that people are different, and the right moment to introduce Python depends on the person as much as the task.
Q: You often reflect on trade-offs in software design. How does that mindset influence how you approach Python around models?
I try to never make a design decision without asking: what am I trading away? That mindset applies whether I’m designing a Python library or writing a 20-line script. The most important trade-off I keep coming back to is the right level of abstraction. Too low, and the code becomes painful to use; reading a dfs file used to require around 50 lines of boilerplate. Too high, and you lose composability.
MIKE IO was designed to hit that balance; a single line to read a file but built on top of pandas, so the pieces connect naturally to the rest of the ecosystem. Pandas is basically like a Swiss army knife of tools related to tabular data like database tables, Excel files).
I don’t subscribe to the “Not Invented Here” mindset where developers avoid using external libraries or tools, but I think hard before introducing a new dependency. Every dependency is a trade-off too.
Q: What challenges have you seen when Python is used in modelling workflows?
The challenges are real, especially when people are coming from GUIs and Excel. Scripts written for yourself tend to have hardcoded paths, assumptions that only make sense on your own machine, and no error handling. They work once, for you, and then become a burden for anyone else who tries to use them. There’s also a learning curve that’s easy to underestimate; Python looks approachable but writing code that others can read and reuse is a different skill from writing code that just runs. I’ve seen a lot of scripts that solved the right problem but couldn’t outlive the person who wrote them. That’s not an argument against Python; it’s an argument for investing in the basics of good scripting practice alongside the technical skills, which is something I try to actively support through knowledge sharing across the organisation and the Python community.
Q: How can Python help maintain scientific intent as modelling results are reused or revisited?
Python code is a much better record of what was done than a Word document. The assumptions are in the code, the steps are explicit, and anyone can re-run it and get the same result. A Word document describes what someone did; Python code is what they did. When modelling results need to be revisited or handed to someone else, that difference matters a lot.
Q: Python has known limitations. Why do you continue to use it in your work?
Python has real limitations. The two-language problem is a genuine one. Python is great for building workflows, but for performance-critical parts you often need another language, and managing both is a real cost. Python is slow for heavy computation, and the honest answer is that most of the fast code in Python isn’t Python at all. numpy, pytorch, and many scientific libraries are compiled code under the hood. At DHI, we do the same, with low-level C and C++ libraries handling the performance-critical parts.
There are languages I genuinely love; the elegance of dplyr and ggplot2 in R, Ruby’s beautiful syntax, Julia’s mathematical notation and clean solution to the two-language problem, and Matlab was the standard in simulation for a long time. But that comparison is almost unfair; R, Julia and Matlab win in their narrow domains precisely because they are designed for them, tailored to statistics, math or simulation.
Python wins by being good enough at everything. And collaboration matters; it would be counter-productive for me to work in a language that the people around me don’t use. Python is the de facto standard in machine learning and geospatial, and for a company like DHI, working at the intersection of water, environment and data, that’s exactly where we need to be. Geospatial is relevant to almost everything we do today; ML and agentic AI will be part of everyone’s work life very soon, and that ecosystem is built on Python. That’s not a compromise; it’s the right choice.
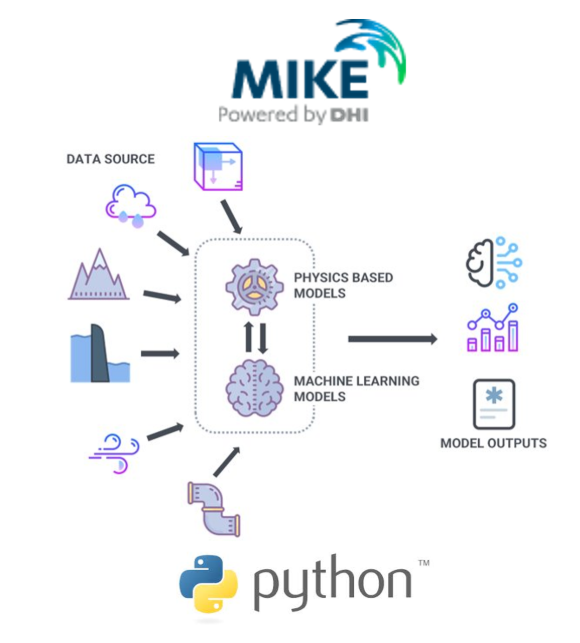
Python is not a modelling method, but it plays an important supporting role in many workflows.
Used carefully, it can help make modelling work more transparent, repeatable and easier to revisit, which is often what determines whether modelling results remain useful over time.




